What does Yann LeCun think about AGI? A summary of his talk, "Mathematical Obstacles on the Way to Human-Level AI"
This is a summary of Yann LeCun's talk "Mathematical Obstacles on the Way to Human-Level AI". I've tried to make it more accessible to people who are familiar with basic AI concepts, but not the level of maths Yann presents. You can watch the original talk on YouTube.
I disagree with Yann, but I have tried to represent Yann's arguments as faithfully as possible. I think understanding people who differ in opinion to you is incredibly important for thinking properly about things.
At the bottom of the post I include Gemini 2.5 Pro's analysis of my summary. In short:
The summary correctly identifies the core arguments, uses LeCun's terminology [...], and reflects the overall tone and conclusions of the talk
Why Yann LeCun thinks LLMs will not scale to AGI
LLMs use deep learning for base and fine-tuning, which is sample inefficient (need to see many examples before learning things). Humans and animals learn from way fewer samples.
LeCun's slide

LLMs are primarily trained on text, which doesn't carry as much raw data as other formats. To get AGI we need to train models on sensory inputs (e.g. videos). Humans see more data when you measure it in bits.
LeCun's slide

The setup for LLMs has them predict the next token. But this means they are predicting in a space with exponentially many options, of which only one is correct. This means they are almost always incorrect. And similarly for images/videos, they have so many options and the world is only partially predictable, that it's not feasible for the model to be correct.
My visualisation

LeCun's slides


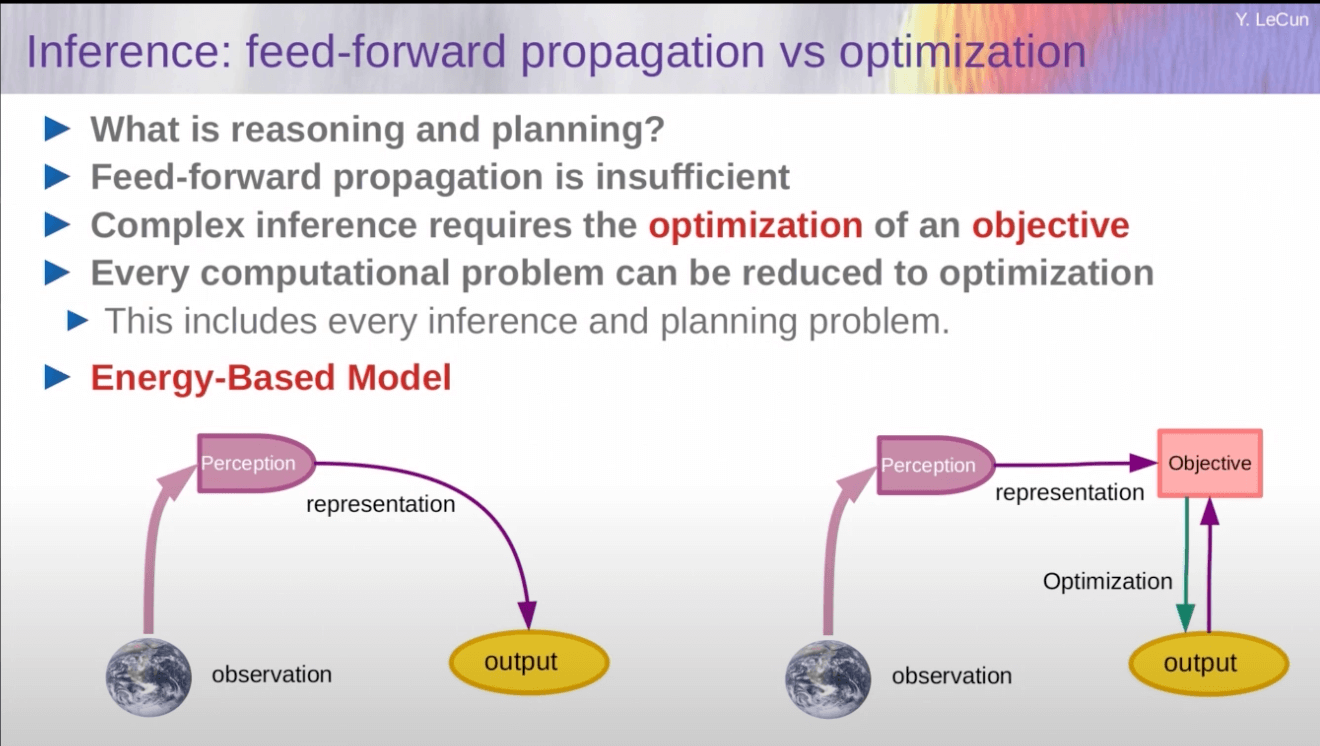
AI systems work the same amount of time on short problems and hard problems. But actually they should work longer on hard problems.
- He thinks chain of thought is a trick that he implies isn't really solving it. (video timestamp: 19:33)
- Instead thinks we should have AI systems be using optimization/search algorithms against an objective when posed with a problem, rather than using feed forward neural networks. And then the search process can continue until it solves the problem (which means it can work longer on a hard problem).
LeCun's slide
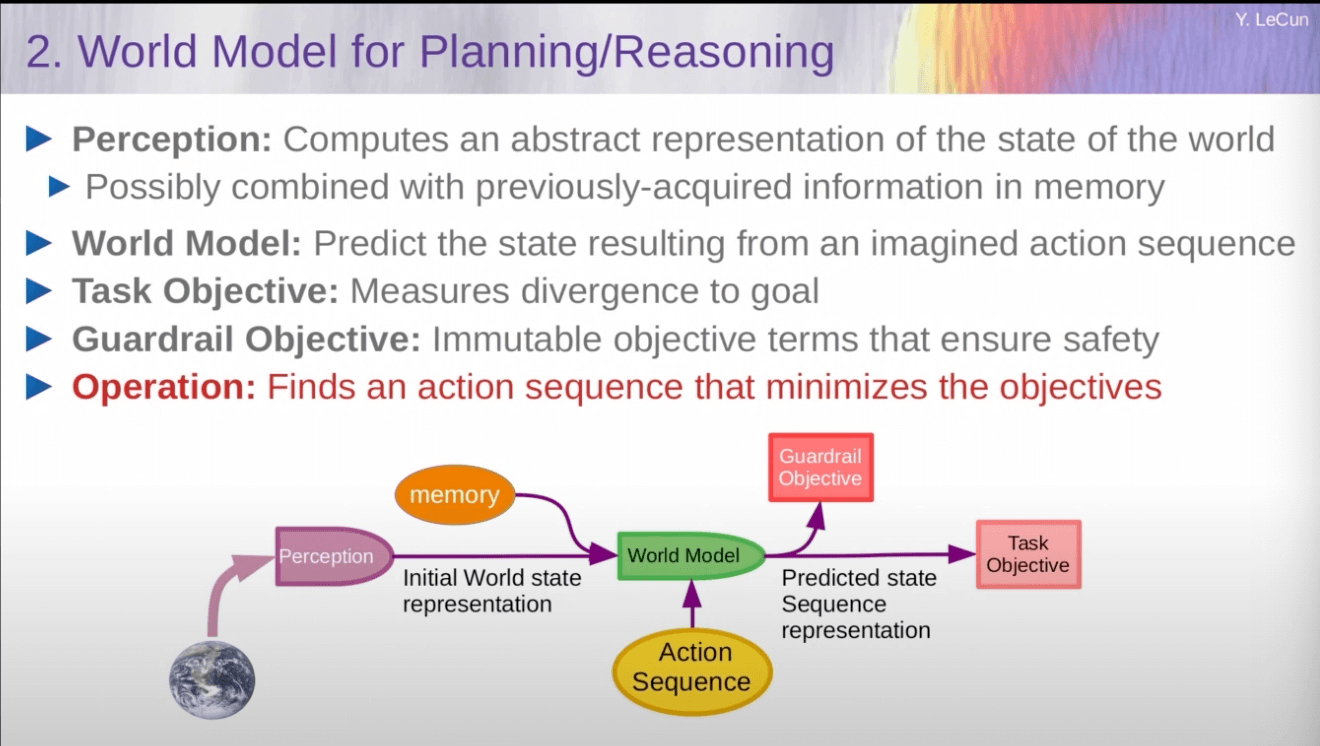
How Yann LeCun thinks we should build AGI
We need to model it after how humans think
- Sensory inputs (e.g. videos)
- Have access to long term memory via tools
- Should spend some time planning
- Should spend some time reasoning and doing
Needs to be safe and controllable by design
- "Not by fine-tuning, like current AI systems" (video timestamp: 19:01)
The specific architecture he proposes is:
- An AI doing action generation, i.e. "What actions could I take?", output = X, Y, Z
- An AI doing world modelling, i.e. "What will happen in the world if actions X, Y, Z are taken?". Output = world where scenario A happens, world where scenario B happens, etc.
- This takes in:
- The potential actions
- Sensory data about the world
- Data from a memory tool
- (Extension added in a later slide: some random noise that represents latent unpredictability/uncertainty in the world - so your plans are good across different situations)
- This takes in:
- An AI calculating how good a world state would be for an objective, i.e. "How good is scenario A?", output = numeric score
- There are two of these models. One which effectively represents the prompt e.g. 'maximise making paperclips', and one which is for safety e.g. 'don't destroy earth'. These are combined in an unspecified way.
- Glue the above together and keep taking actions this way. Train the models using RL, or use classical algorithms (e.g. graph search, A* search, monte-carlo tree search)
AI should be released open-source, and be used as an amplifier of human intelligence.
- Vision of the future: all interactions with the digital world are through AI assistants
- Wants a diverse set of AI assistants for linguistic, cultural and value system diversity
Appendix: Gemini's analysis of my summary
Prompt: My summary above + YouTube video + "Is the above an accurate summary of Yann LeCun's views based on the attached video? If not, where can it be made more accurate?"
Response:
Yes, the provided summary is an accurate and faithful representation of Yann LeCun's views as presented in the video transcript.
Here's a breakdown confirming the key points:
Sample Inefficiency of Deep Learning/LLMs: LeCun explicitly states machine learning (in its current supervised/RL forms) "sucks" compared to humans/animals (5:06-5:18) and requires vast amounts of labeled data or trials, unlike quick human learning (6:41). The summary captures this inefficiency point correctly.
Insufficient Data Type & Volume (Text vs. Sensory): He directly compares the data volume processed by a 4-year-old child through vision (estimated at 1.1E14 bytes) with the training data of LLMs (estimated around 6.0E13 bytes, rounded up to 1E14 for comparison) and emphasizes that sensory data holds far more information than text (15:16-16:52). The summary accurately reflects this argument.
Next-Token Prediction Limitations & Error Accumulation: LeCun clearly explains the auto-regressive nature of LLMs (10:04-11:24), the exponential divergence problem due to cascading prediction errors (11:24-11:51, especially the P(correct) = (1-e)^n formula), and explicitly calls auto-regressive LLMs "doomed" (12:00). He also mentions the problem of predicting every detail in high-dimensional spaces like video (33:41-33:49). The summary correctly captures these criticisms.
Inability to "Think Hard" & Skepticism of Chain-of-Thought: He contrasts the fixed feed-forward computation per token in LLMs (19:13-19:31) with the need for variable computation for complex tasks (20:13-20:28). He refers to Chain-of-Thought as a "trick" to make LLMs produce more tokens, implying it's a workaround rather than a fundamental solution (19:31). The summary accurately reflects this.
AGI via LLMs Infeasible: This follows directly from the previous points and is strongly stated with phrases like "doomed" (12:00), "we're missing something really big" (12:24), the comparison of data types (16:42), and the explicit slide advice "IF YOU ARE INTERESTED IN HUMAN-LEVEL AI, DON'T WORK ON LLMs" (54:14). The summary is accurate here.
LeCun's Proposed Architecture (JEPA/Objective-Driven): He details the components like perception, world model, cost/objective functions (including task and guardrail objectives), and an actor that performs optimization/planning (inference through optimization) multiple times (24:47 - 27:31, 31:03). He emphasizes learning world models from sensory input (16:42, 54:36) and the need for planning and reasoning capabilities (55:52). The use of memory (26:21, 31:19) and handling uncertainty via latent variables (28:23) are also mentioned. The summary correctly lists these components and their interactions.
AMI vs AGI & Open Source: He explicitly states the preference for the term AMI (Advanced Machine Intelligence) over AGI because human intelligence isn't truly general (18:25). He also strongly advocates for open-source platforms (55:41-56:02). This is accurately captured.
The summary correctly identifies the core arguments, uses LeCun's terminology (like JEPA, auto-regressive, world models, guardrails), and reflects the overall tone and conclusions of the talk based on the transcript.